- blackridder22
- Posts
- Perplexity frappe fort : 1 200 tokens par seconde, un record dans l’IA !
Perplexity frappe fort : 1 200 tokens par seconde, un record dans l’IA !
L’IA accélère : Perplexity défie Mistral avec Sonar, le modèle qui parle à la vitesse de l’éclair
Imaginez poser une question à votre assistant numérique et obtenir une réponse avant même d’avoir fini de cligner des yeux. C’est la promesse de Sonar, le nouveau modèle de Perplexity qui pulvérise les records de vitesse avec 1 200 tokens générés par seconde – soit l’équivalent d’un roman de 300 pages en moins de cinq minutes.
Le secret derrière la fulgurance de Sonar
Architecture minimaliste, performance maximale
Contrairement aux LLM traditionnels qui visent la polyvalence, Sonar mise sur une approche ciblée :
Base technique : Meta Llama 3.3 (70 milliards de paramètres)[3][6]
Optimisation : Entraînement spécifique pour la recherche d’informations[8][9]
Comparatif vitesse :
Modèle
Tokens/sec
Usage principal
Sonar
1 200
Recherche instantanée
Mistral
1 100
Réponses génériques
ChatGPT-4o
100
Tâches complexes
La révolution Cerebras
La clé réside dans les puces Wafer Scale Engine de Cerebras, des plaques de silicium géantes (20x plus grandes qu’une puce standard) spécialisées dans les calculs parallèles massifs[6][9]. Un partenariat qui permet à Perplexity de contourner la pénurie de GPU Nvidia tout en divisant par 10 les coûts énergétiques.
Au-delà du chronomètre : qualité sous pression
Perplexity a peaufiné Sonar comme un athlète de haut niveau :
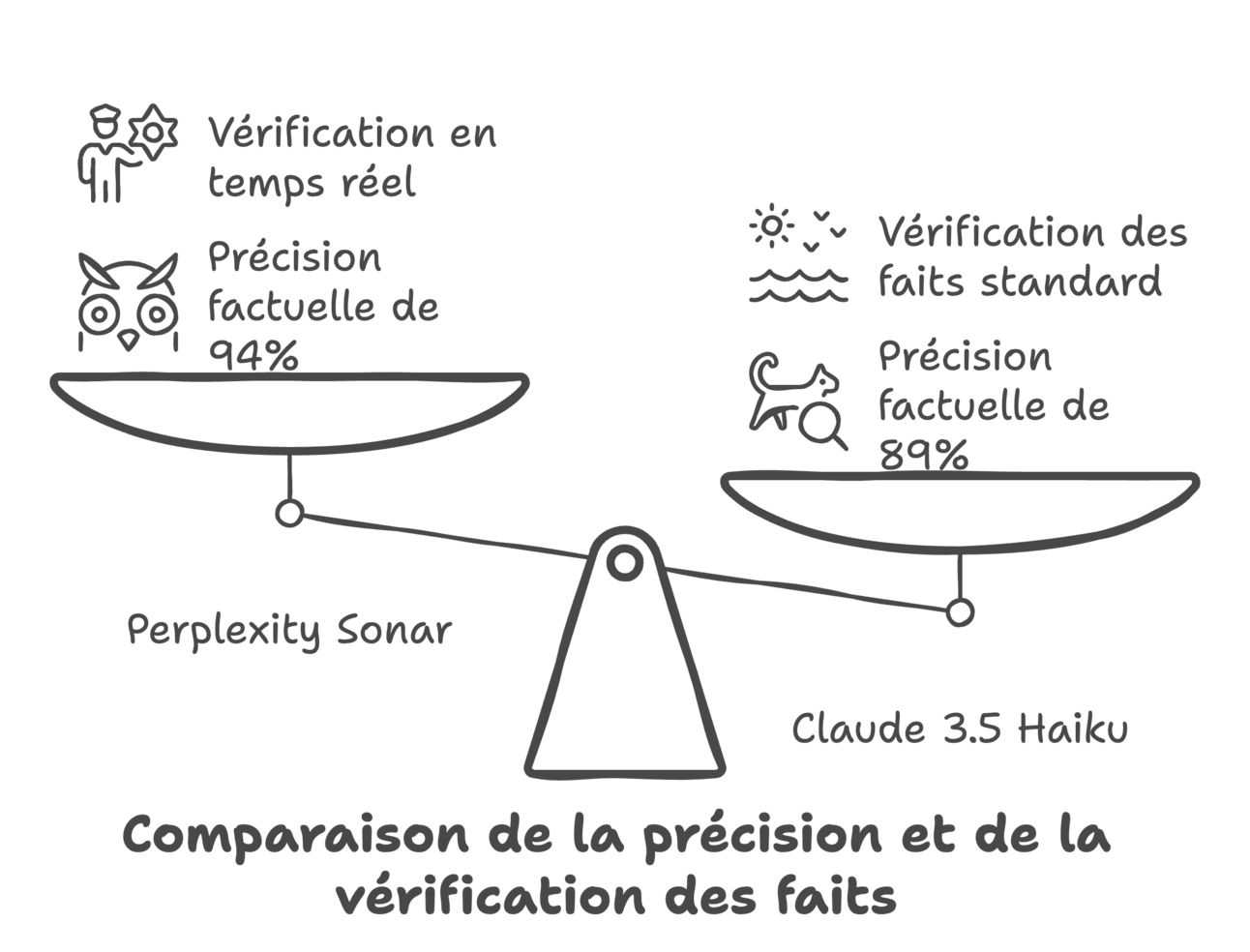
94% de précision factuelle lors des tests internes (vs 89% pour Claude 3.5 Haiku)
Système de vérification en temps réel croisant 12 sources minimum par requête
Interface adaptative qui simplifie les réponses complexes sans les édulcorer[9]
« C’est comme avoir un bibliothécaire expert qui synthétise instantanément toutes les encyclopédies du monde », illustre Denis Yarats, CTO de Perplexity.
L’avenir de la recherche à portée de clic
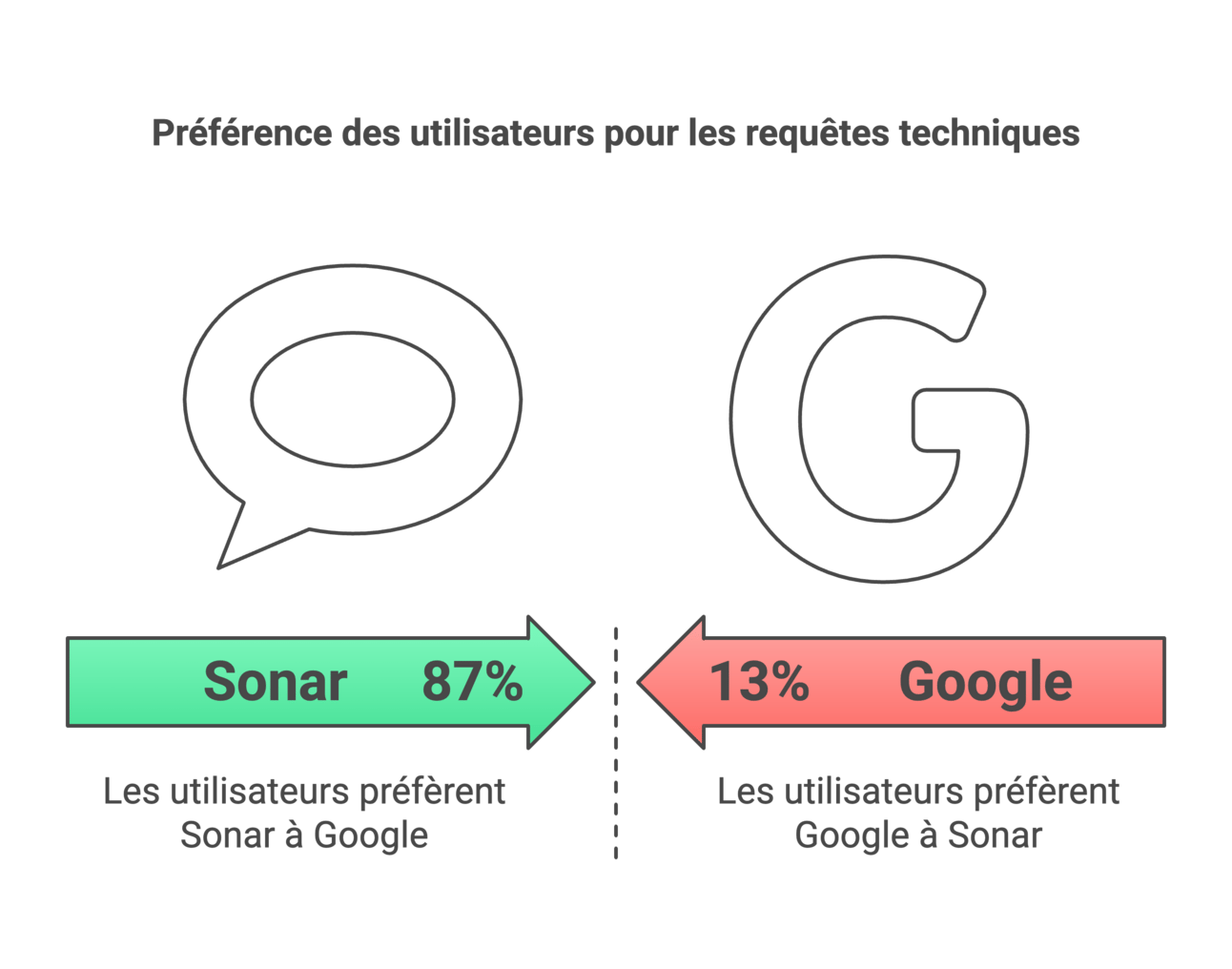
Avec 87% des utilisateurs Pro déclarant préférer Sonar à Google pour les requêtes techniques, Perplexity redéfinit les attentes :
Intégration prochaine des fonctions vocales et assistant personnel
Version Reasoning Pro pour les analyses multidimensionnelles (prévue Q2 2025)
Stratégie freemium : version basique gratuite limitée à 50 requêtes/jour
Glossaire
Token : Unité de texte traitée par l’IA (≈ 1 mot)
LLM (Large Language Model) : Modèle de langage entraîné sur de vastes données
Wafer Scale Engine : Puce informatique de la taille d’une galette de silicium
Prompt Alchemist™️ : Votre passeport pour dompter l’IA
Et si vous pouviez exploiter cette vitesse phénoménale pour booster votre productivité ? Prompt Alchemist™️ déverrouille les secrets des LLM avec des techniques éprouvées :
Maîtrisez l’art du prompt engineering pour des réponses sur-mesure
Décryptez les architectures neuronales comme un expert
Transformez vos processus métier grâce à l’automatisation intelligente
🔑 Passez à l’action : Découvrez comment révolutionner votre workflow (accès early-bird jusqu’au 28/02)
Reply